2026年4月24日 AWS アップデート情報
はじめに
2026年4月24日の AWS アップデートは 12件。データ分析基盤まわりとエンタープライズ向けの ID/ネットワーク統合に動きがあった回です。
今回深掘りするのは次の 2 つ。
- Amazon Athena のフェデレーテッドクエリがマネージドコネクタに対応 — 12 データソースに対するコネクタリソースを AWS 側が作成・管理
- Amazon Redshift が Apache Iceberg テーブルの UPDATE/DELETE/MERGE をサポート — S3 Tables 含む Iceberg テーブルに直接 DML 可能
データレイク/データウェアハウス周辺のオペレーションが、外部エンジンを経由せずに完結しやすくなる方向の変更です。他にも SageMaker Unified Studio の IdC ドメイン対応とノートブックカーネルの VPC 対応、S3 のチェックサムアルゴリズム 5 種追加、Amazon Quick の ACL 権限検証機能追加などが入っています。
注目アップデート深掘り
1. Amazon Athena のフェデレーテッドクエリがマネージドコネクタに対応
何が変わるのか
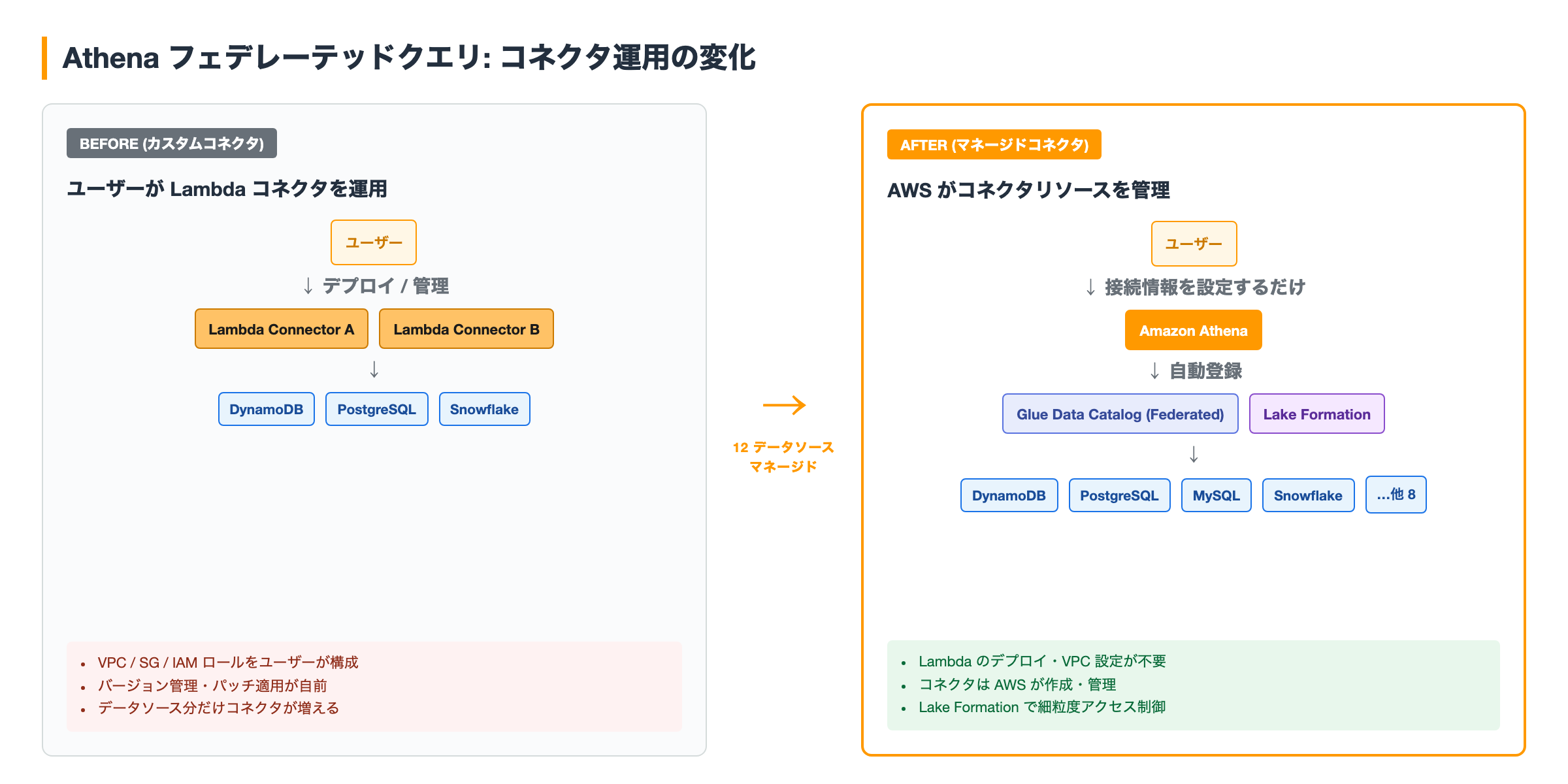
これまで Athena でフェデレーテッドクエリを実行するには、データソースごとに Lambda 関数ベースのコネクタをユーザー自身がデプロイし、VPC 設定・IAM ロール・バージョン管理などを回す必要がありました。コネクタのデプロイ・運用コストがフェデレーテッドクエリ導入の障壁になっていたケースは多いと思います。
今回のアップデートでは、Athena が 12 データソース向けのマネージドコネクタ を提供します。公式発表で明示されているデータソースは Amazon DynamoDB、PostgreSQL、MySQL、Snowflake を含む 12 種類(全リストは公式ドキュメントを参照)。マネージドコネクタは AWS Glue Data Catalog のフェデレーテッドコネクタとして AWS 側が作成・管理するため、ユーザーのアカウントにコネクタ用の Lambda 関数や IAM ロールをデプロイする必要がなくなります。
使い方
公式の案内によると、手順は以下の流れです。
- Athena でデータソースに対する接続(connection)を作成する
- Athena が自動的にコネクタリソースをセットアップし、AWS Glue Data Catalog にフェデレーテッドカタログとして登録する
- S3 上のデータと並べてクエリできるようになり、必要に応じて AWS Lake Formation できめ細かいアクセス制御を設定できる
クロスソースクエリのイメージは以下のような形です(カタログ名は自由に命名できます)。
-- S3 上の売上データと DynamoDB の顧客マスタを結合
SELECT
sales.order_id,
sales.amount,
customers.name,
customers.email
FROM
"s3_catalog"."sales_db"."orders" AS sales
JOIN
"my-dynamodb-catalog"."default"."customers" AS customers
ON sales.customer_id = customers.customer_id
WHERE
sales.order_date >= DATE '2026-04-01';
利用可能リージョン
マネージドコネクタ版のフェデレーテッドクエリは、Athena が提供されている全リージョンで利用可能。ただし AWS GovCloud (US) リージョンと中国リージョンは対象外 と公式に明記されています。
Lake Formation との統合
既存の Lake Formation の機能を使って、フェデレーテッドカタログに対してもテーブル/カラム単位の権限制御が可能です。コネクタ自体の管理から解放されつつ、細粒度のアクセス制御は Lake Formation 側で一元化できるので、エンタープライズのガバナンス要件に対しても投げやすくなります。
2. Amazon Redshift が Apache Iceberg テーブルの UPDATE/DELETE/MERGE に対応
何ができるようになったか
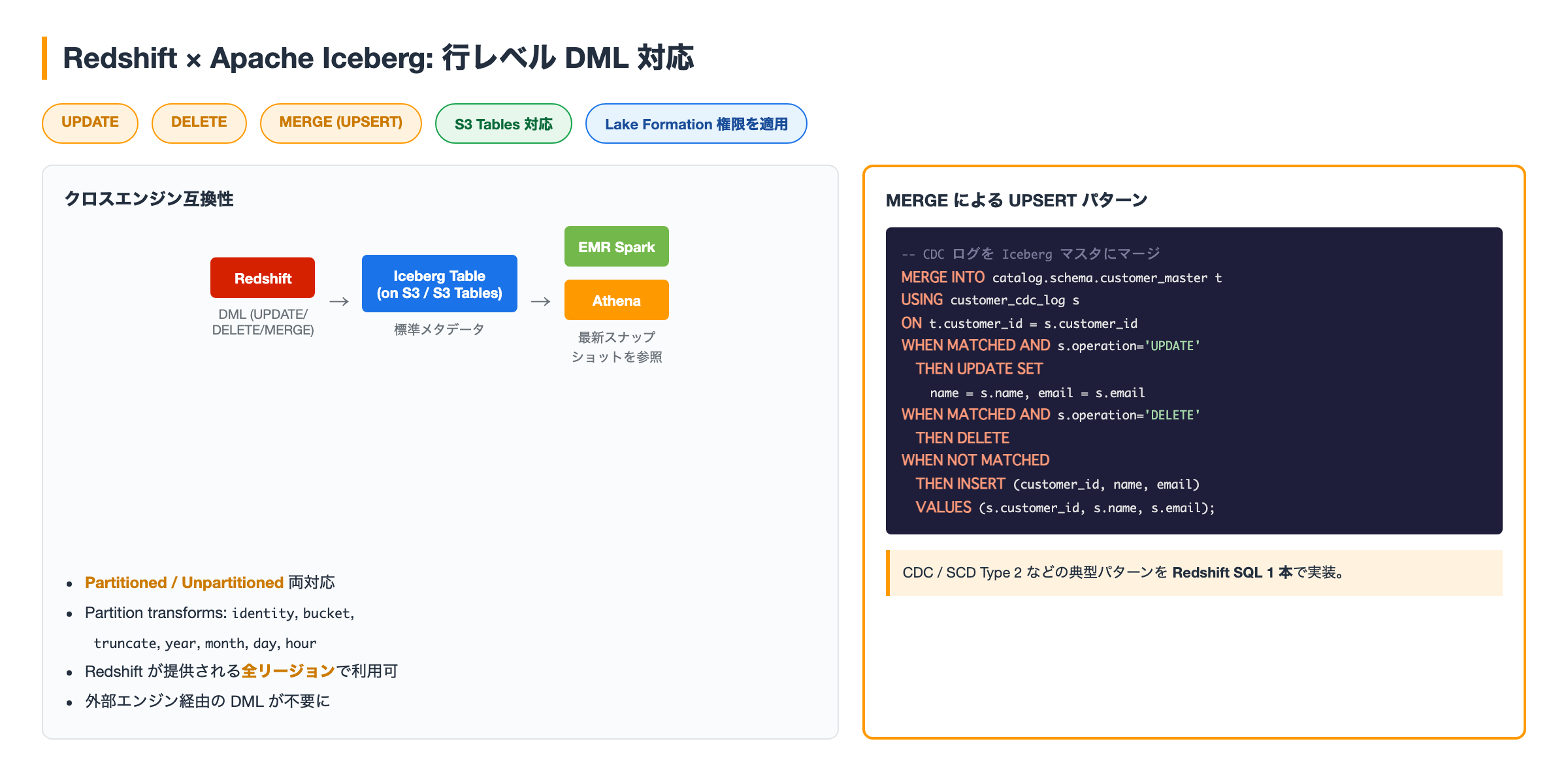
これまで Redshift から Iceberg テーブルに対しては読み取りと INSERT は可能でしたが、行レベルの UPDATE / DELETE / MERGE には未対応でした。そのため、Iceberg テーブルの個別レコード更新が必要な場合は EMR や Athena などの別エンジンを経由する必要があり、データパイプラインが複雑化していました。
今回のアップデートでポイントになるのは以下です(公式発表より)。
- UPDATE / DELETE / MERGE(UPSERT)を Redshift から直接実行可能に
- partitioned / unpartitioned の両方の Iceberg テーブルに対応、S3 Tables も対象
- サポートされる partition transforms:
identity,bucket,truncate,year,month,day,hour - Redshift が更新した結果は、Amazon EMR / Amazon Athena など他の Iceberg 互換エンジンから読める(クロスエンジン互換性は維持)
- AWS Lake Formation の権限が Iceberg 書き込み操作にも適用される
- Redshift が提供されている全リージョンで利用可能
MERGE による UPSERT
MERGE は CDC(変更データキャプチャ)やゆっくり変化するディメンション(SCD Type 2)のような、よくあるデータ統合パターンを 1 文で書けるのが利点です。
-- CDC データを Iceberg テーブルにマージ
MERGE INTO catalog.schema.customer_master AS target
USING (
SELECT customer_id, name, email, last_updated, operation
FROM catalog.schema.customer_cdc_log
WHERE processed_at > (SELECT MAX(last_sync) FROM sync_metadata)
) AS source
ON target.customer_id = source.customer_id
WHEN MATCHED AND source.operation = 'UPDATE' THEN
UPDATE SET
name = source.name,
email = source.email,
last_updated = source.last_updated
WHEN MATCHED AND source.operation = 'DELETE' THEN
DELETE
WHEN NOT MATCHED AND source.operation = 'INSERT' THEN
INSERT (customer_id, name, email, last_updated)
VALUES (source.customer_id, source.name, source.email, source.last_updated);
具体的な SQL 構文は公式ドキュメント(「Writing to Apache Iceberg tables」セクション)に案内があります。
クロスエンジン互換性の意味
Iceberg のトランザクションログ(メタデータ)は標準化されているため、Redshift で MERGE した結果もそのまま EMR Spark や Athena から最新スナップショットとして参照できます。データレイクの中心に Iceberg を置いて、書き込みエンジンを用途別に使い分ける構成が、今回のアップデートで Redshift にも拡張された形です。
SRE視点での活用ポイント
Athena マネージドコネクタの運用シーン
障害調査でアプリケーションログ(S3)、セッション情報(DynamoDB)、トランザクションログ(RDS)を横断して SQL 一本で見たい、というのはよくあるユースケース。これまではコネクタのデプロイ作業が先に立ち塞がっていて、手を出しにくい場面もあったと思います。マネージドコネクタで初期構築のハードルが下がることで、「横断的な調査クエリ」をライトに使い捨てできる選択肢が増えます。
ただし、本番データベースへの直接クエリは負荷が気になるところ。Read Replica を接続先にする、タイムアウトを短めに設定する、頻繁に使うなら事前に Athena CTAS で S3 に集計テーブルを作っておく、あたりは従来どおり考慮すべきポイントです。Terraform でフェデレーテッドカタログの接続情報を IaC 化しておけば、環境ごとの再現性も担保できます。
Redshift Iceberg DML のデータ品質管理
データレイクの重複排除や整合性チェックを、定期バッチで Redshift から MERGE 実行する構成が組みやすくなりました。CloudWatch アラームでエラー率やスキャン行数を監視し、異常なデータ増加を早期に拾う運用にも組み込めます。Redshift のシステムテーブル(STL_QUERY など)からクエリ実行統計を見て、パフォーマンス劣化の兆候を追うのも有効です。
既存パイプラインで EMR を使って Iceberg テーブルの DML をさばいていた場合は、Redshift への統合でエンジン数を減らせる可能性があります。一方、リアルタイム性が厳しいユースケースでは、Iceberg のスナップショット間隔・コンパクション頻度が性能に響くので、導入前に負荷テストを通しておくのが無難です。
全アップデート一覧
以下の表に登場する、やや馴染みの薄いサービスの補足です。
AWS Parallel Computing Service (PCS) とは? AWS 上で HPC(ハイパフォーマンスコンピューティング)クラスターを構築・運用するためのマネージドサービス。Slurm などのスケジューラを AWS が管理する形で提供し、シミュレーション・CAE・ゲノム解析などの大規模並列処理に使われます。
Amazon Quick とは? ACL(アクセス制御リスト)に対応したナレッジベースを管理できる AWS のサービス。SharePoint や Google Drive などの外部データソースと連携し、ドキュメント単位の権限を維持したまま横断検索できます。Amazon Q(生成 AI アシスタント)とは別サービスなので混同に注意。
Amazon SageMaker Unified Studio とは? SageMaker の各種機能(ノートブック、データカタログ、ジョブ管理、AI 開発ツール)を統合した Web IDE。IAM ドメインと IAM Identity Center(IdC)ドメインの 2 つの認証形態に対応しています。
まとめ
方向性は「データ分析基盤の運用負荷削減」と「SageMaker Unified Studio のエンタープライズ対応」の 2 軸で読み取れます。
Athena のマネージドコネクタと Redshift の Iceberg DML 対応は、データレイク/データウェアハウス境界での「誰がどのエンジンから書くか」という設計の選択肢を広げる変更です。Athena 側はコネクタ運用の手離れを、Redshift 側は Iceberg への書き込みを Redshift 内で完結できるようになる点が効いてきます。S3 Tables 対応も含まれているので、S3 Tables を採用済みのチームにとっては特に現実的な選択肢が増えた格好です。
SageMaker Unified Studio の IdC ドメイン対応・ノートブックカーネルの VPC 対応・複数コードスペース対応は、エンタープライズ向けの統制とネットワーク分離を気にする現場で採用判断のハードルが下がる方向の変更です。既に Unified Studio 上で検証を進めているチームは、IdC 移行の前提条件を棚卸しておくと次のステップに進みやすいはずです。
SRE 視点では、Athena のマネージドコネクタで「横断調査クエリ」のセットアップコストが下がることが実運用に効きそうです。まずは手元の検証環境で 1 データソース分だけ接続を試して、既存のカスタムコネクタとの切替で運用が簡素化できるかを見るのが現実的な入り口です。