2026年4月23日 AWS アップデート情報
はじめに
2026年4月23日の AWS アップデートは 14件。EC2・EKS・CloudWatch まわりに「運用の認知負荷を減らす」系の変更がまとまって入った日でした。
今回取り上げるのは次の 3 つ。
- Amazon EC2 マネージドリソース可視性設定 — EKS/ECS/Lambda/WorkSpaces が裏で作る EC2 リソースをコンソール/API から隠せる
- Amazon EKS Hybrid Nodes Gateway — オンプレと AWS にまたがる Kubernetes のルーティングを Helm chart で自動化
- CloudWatch Pipelines の AI 支援設定 — 自然言語でログパイプラインのプロセッサ設定を生成
共通しているのは「今まで自前で頑張っていた部分を AWS 側で引き取る」方向の変更です。責任分界の整理、運用の自動化、マネージド化の一段深い適用、どれもここ数年の流れの延長線上にあります。
注目アップデート深掘り
Amazon EC2 マネージドリソース可視性設定

何が変わるのか
これまで EKS / ECS / Lambda / WorkSpaces などのマネージドサービスが裏で作る EC2 リソース(インスタンス、EBS ボリューム、ENI など)は、自分で作ったリソースと区別なく EC2 コンソールや API 応答に並んでいました。棚卸し・コスト分析・自動化スクリプトのフィルタリングで、毎回「これは AWS 管理だから触らない」という判別を人手でやる必要があったわけです。
今回のアップデートでは、新規のマネージドリソースがデフォルトで非表示(HIDDEN)になります。共有責任モデル上「AWS 側が管理しているリソース」は、そもそも自分のコンソールに出てこない状態が標準になります。
実装と検証手順
まず、現在の設定状態を確認します。
$ aws ec2 get-managed-resource-visibility-settings --region us-east-1
デフォルトでは、新規マネージドリソースは非表示(hidden)に設定されています。既存のマネージドリソースの表示状態を変更する場合は、以下のコマンドを実行します。
$ aws ec2 put-managed-resource-visibility-settings \
--region us-east-1 \
--visibility-setting HIDDEN \
--resource-types "instance" "volume" "snapshot" "network-interface"
設定前後でのdescribe-instancesの出力を比較してみましょう。
設定前(マネージドリソース表示):
$ aws ec2 describe-instances --region us-east-1 --output table
# EKSノード、Lambdaの実行環境、自己管理インスタンスがすべて混在して表示される
設定後(マネージドリソース非表示):
$ aws ec2 describe-instances --region us-east-1 --output table
# 自己管理インスタンスのみが表示される
タグベースでフィルタリングしている既存スクリプトへの影響も検証が必要です。例えば、Cost Explorerやリソースタグベースのレポート生成スクリプトは、マネージドリソースが非表示になっても引き続き正しく動作するかを確認しましょう。
import boto3
ec2 = boto3.client('ec2', region_name='us-east-1')
# 自己管理インスタンスのみを取得
response = ec2.describe_instances(
Filters=[
{'Name': 'tag:Environment', 'Values': ['production']},
{'Name': 'tag:ManagedBy', 'Values': ['terraform']}
]
)
for reservation in response['Reservations']:
for instance in reservation['Instances']:
print(f"Instance ID: {instance['InstanceId']}, State: {instance['State']['Name']}")
ユースケース別の推奨設定
| ユースケース | 推奨設定 | 理由 |
|---|---|---|
| EKS/ECS中心の環境 | HIDDEN | ノードは自動スケーリングされるため、EC2コンソールでの管理は不要 |
| Lambda中心の環境 | HIDDEN | Lambda実行環境のEC2リソースはAWS完全管理 |
| ハイブリッド環境 | VISIBLE | 一時的に可視化してリソース棚卸しを実施後、HIDDENに切り替え |
| セキュリティ監査 | VISIBLE | すべてのリソースを可視化して包括的な監査を実施 |
Note: 設定変更は既存のマネージドリソースには遡及的に適用されません。新規プロビジョニングされるリソースからのみ適用されます。
Amazon EKS Hybrid Nodes Gateway
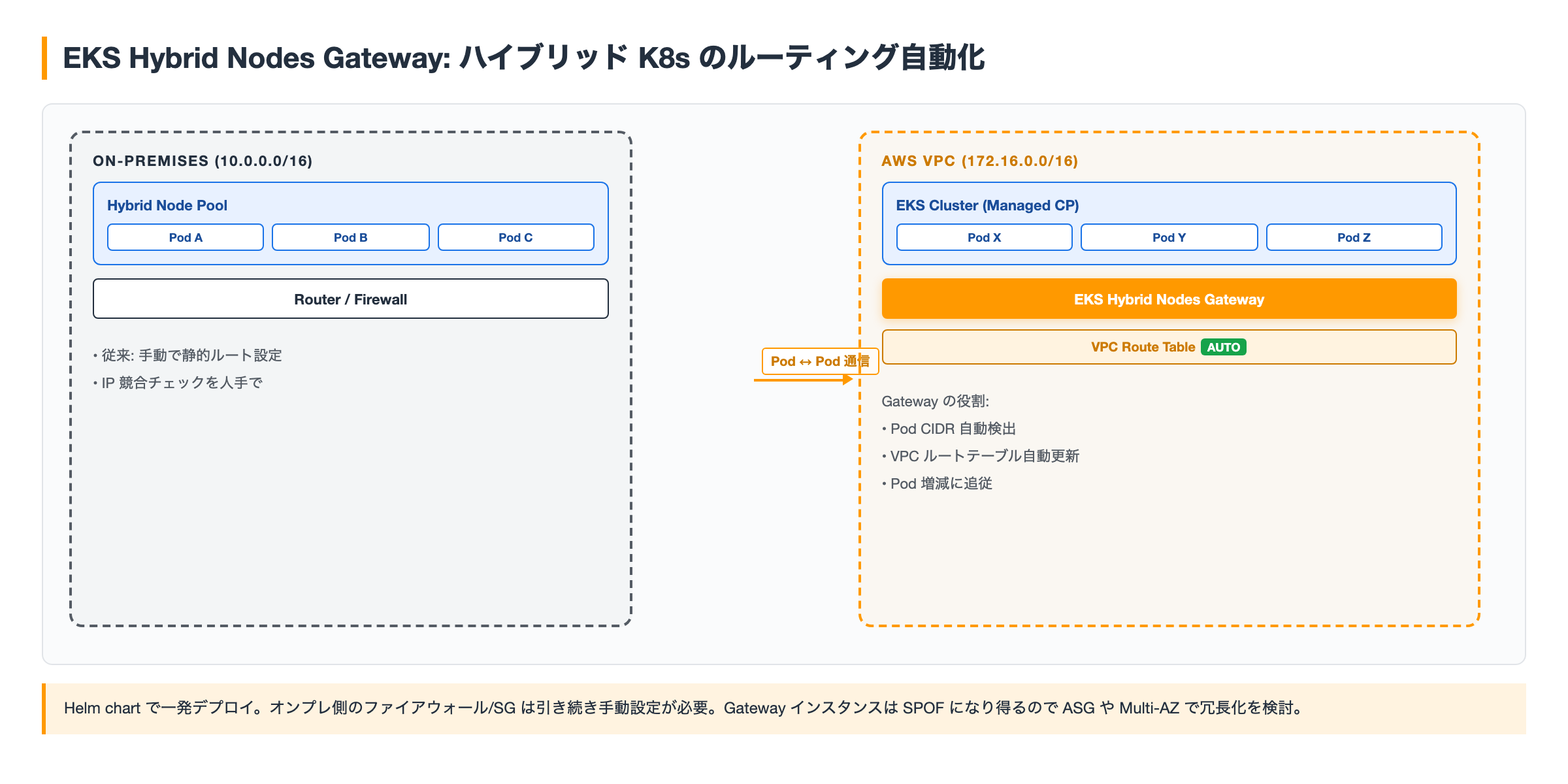
ハイブリッド Kubernetes の課題
オンプレミスと AWS にまたがる Kubernetes 環境では、Pod 間通信のためにネットワーク設定を手で回す必要があります。従来の流れはこんな感じでした。
- VPCルートテーブルの手動更新
- オンプレミスルーターでの静的ルート設定
- IPアドレス範囲の競合回避
- Pod動的スケーリング時のルート再設定
Amazon EKS Hybrid Nodes Gatewayは、これらをHelm chartで自動化します。
デプロイと動作検証
まず、EKS Hybrid Nodes環境をセットアップします。
# EKSクラスターのコンテキストを設定
$ kubectl config use-context my-eks-cluster
# Helmリポジトリを追加
$ helm repo add eks-hybrid-nodes https://aws.github.io/eks-hybrid-nodes
$ helm repo update
# ゲートウェイをデプロイ
$ helm install eks-hybrid-gateway eks-hybrid-nodes/hybrid-nodes-gateway \
--namespace kube-system \
--set vpc.id=vpc-0123456789abcdef \
--set subnet.id=subnet-0123456789abcdef \
--set onpremises.cidr=10.0.0.0/16
デプロイ後、VPCルートテーブルが自動的に更新されていることを確認します。
$ aws ec2 describe-route-tables --route-table-ids rtb-0123456789abcdef --query 'RouteTables[0].Routes'
オンプレミスからAWS VPC内のPodへの疎通確認:
# オンプレミスノードから実行
$ kubectl run test-pod --image=nginx --restart=Never
$ kubectl get pod test-pod -o wide
# PodのIPアドレスを確認
$ curl http://<pod-ip>:80
# nginxのデフォルトページが返ってくることを確認
アーキテクチャと通信フロー
EKS Hybrid Nodes Gatewayは、EC2インスタンス上で動作する軽量なルーティングコンポーネントです。以下のような役割を担います:
- ルート自動検出: Kubernetesクラスター内のPod CIDR範囲を自動検出
- VPC統合: AWS VPCのルートテーブルを自動更新
- 動的スケーリング対応: Pod数が増減しても、ルートテーブルを自動的に調整
- ヘルスチェック: ゲートウェイ自身の健全性を監視し、障害時は自動フェイルオーバー
Terraformでのデプロイ例:
resource "aws_instance" "hybrid_gateway" {
ami = data.aws_ami.amazon_linux_2023.id
instance_type = "t3.medium"
subnet_id = aws_subnet.public.id
user_data = <<-EOF
#!/bin/bash
# Helmとkubectlをインストール
curl https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3 | bash
# EKSクラスターに接続
aws eks update-kubeconfig --name ${var.cluster_name} --region ${var.region}
# Hybrid Nodes Gatewayをデプロイ
helm install eks-hybrid-gateway eks-hybrid-nodes/hybrid-nodes-gateway \
--namespace kube-system \
--set vpc.id=${var.vpc_id} \
--set onpremises.cidr=${var.onpremises_cidr}
EOF
tags = {
Name = "eks-hybrid-gateway"
Role = "kubernetes-networking"
}
}
Note: ゲートウェイはオープンソースで公開されており、GitHubリポジトリでカスタマイズやコントリビュートが可能です。追加料金は不要で、基盤となるEC2インスタンスとデータ転送料のみが課金対象です。
CloudWatch Pipelines AI 支援設定機能
ログパイプライン設定の痛み
CloudWatch Logs でログを加工・変換するには、プロセッサ設定(Grok パターン、JSON 解析、フィールド抽出、データ型変換など)を組み合わせる必要があります。非標準フォーマットのログや、ネストされた JSON フィールドの解析は試行錯誤になりがちで、設定ミスでログが欠損するリスクも付きまとっていました。
AI 支援機能では、自然言語でやりたいことを書くだけで、AI がプロセッサ構成を生成します。
実装例
CloudWatchコンソールでパイプライン作成時に「AI assist」を有効化し、以下のようなプロンプトを入力します:
プロンプト例1:
Parse Nginx access logs in combined format, extract timestamp, status code,
request path, and client IP. Convert status code to integer and mask the last
octet of IP addresses for privacy.
AIが生成する設定例(YAML形式):
processors:
- grok:
match_patterns:
- '%{COMBINEDAPACHELOG}'
- parse_json:
field: message
- convert:
fields:
- field: status
type: integer
- mutate:
gsub:
- field: client_ip
pattern: '\.\d+$'
replacement: '.XXX'
- add_fields:
fields:
pipeline_version: "1.0"
processed_at: "%{@timestamp}"
プロンプト例2:
Extract error level, error code, and message from application logs in format:
[2026-04-23T10:30:45Z] ERROR code=5001 message="Database connection failed"
生成される設定:
processors:
- grok:
match_patterns:
- '\[%{TIMESTAMP_ISO8601:timestamp}\] %{LOGLEVEL:level} code=%{NUMBER:error_code} message="%{GREEDYDATA:error_message}"'
- date:
match:
- timestamp
- ISO8601
- convert:
fields:
- field: error_code
type: integer
サンプルログでの事前検証
AI生成後、デプロイ前にサンプルログで動作確認が可能です。
# サンプルログをテスト
$ aws logs test-pipeline-configuration \
--pipeline-name test-nginx-pipeline \
--pipeline-configuration file://pipeline-config.yaml \
--sample-logs file://sample-nginx-logs.txt
サンプル出力(JSON形式):
{
"ProcessedLogs": [
{
"timestamp": "2026-04-23T10:30:45Z",
"status": 200,
"request_path": "/api/users",
"client_ip": "192.168.1.XXX",
"pipeline_version": "1.0"
}
],
"Errors": []
}
Python SDKでの自動化
import boto3
logs_client = boto3.client('logs')
# AI支援でパイプライン設定を生成
response = logs_client.create_pipeline_with_ai_assist(
pipelineName='application-log-pipeline',
description='Parse application logs in custom format and extract error information',
naturalLanguagePrompt='''
Extract timestamp, log level, error code, and error message from logs.
Mask any email addresses found in the message for privacy.
Add a field indicating the pipeline processing time.
''',
sampleLogs=[
'[2026-04-23T10:30:45Z] ERROR code=5001 message="User user@example.com login failed"',
'[2026-04-23T10:31:20Z] WARN code=2003 message="Cache miss for key abc123"'
]
)
# 生成された設定を確認
print(response['GeneratedConfiguration'])
# テスト実行
test_response = logs_client.test_pipeline_configuration(
pipelineName='application-log-pipeline',
configuration=response['GeneratedConfiguration'],
sampleLogs=response['SampleLogs']
)
print(f"Test passed: {test_response['Success']}")
print(f"Processed logs: {test_response['ProcessedLogs']}")
Note: AI生成された設定は、必ず本番投入前にサンプルログでテストしてください。特殊なエッジケース(タイムゾーン、特殊文字、エスケープシーケンス)には追加調整が必要な場合があります。
SRE視点での活用ポイント
マネージドリソース可視性設定の活用
Terraform やインフラ自動化を組んでいるチームでは、aws_instance の data source クエリに影響が出ることに注意が必要です。「すべての EC2 インスタンスにタグを適用する」といった一括処理を書いている場合、マネージドリソースを除外する明示的なフィルタを足しておくと、意図しないリソースへの操作を防げます。
CloudWatch Alarms やコスト監視ダッシュボードでは、マネージドリソースが非表示になってもメトリクスとコストは従来どおり集計されます。Cost Explorer との整合性も保たれる作り。ただしリソースタグベースでレポートを回している場合、AWS 側のマネージドリソースのタグ付けルールに合わせて、レポート側のロジックを見直すのが無難です。
障害対応のランブックで「EC2 コンソールから異常なインスタンスを特定する」手順がある場合、設定変更後は自己管理インスタンスだけが表示されるため、調査範囲が最初から絞り込まれた状態になります。MTTR の短縮に効いてくる変更です。
EKS Hybrid Nodes Gateway の運用改善
ハイブリッド Kubernetes 環境の運用で地味に重いのが、ネットワークチームとアプリケーションチームの調整コストです。Pod 追加のたびにルート変更依頼、というフローは自動化とは相性が悪い。Hybrid Nodes Gateway を入れると、DevOps チームが Kubernetes マニフェストをデプロイするだけでネットワーク設定が追従する状態になります。
注意点は 2 つ。1つ目は、オンプレ側のファイアウォールルールやセキュリティグループは引き続き手動設定が必要な点。ゲートウェイ EC2 インスタンスへの通信許可(TCP/443、UDP/500 など)を事前に確認しておきます。2つ目は、ゲートウェイインスタンスは SPOF になり得るので、ASG や Multi-AZ 配置での冗長化を検討したほうがいい点。
障害時の挙動を整理しておくのも実用的です。オンプレ側で障害が起きた場合、AWS 側の Pod はそのまま動き続けます。AWS 側で障害が起きてもオンプレ側のワークロードは独立して動作する。この部分的な冗長性を前提にした障害対応手順をあらかじめ書いておくと、実運用で効いてきます。
CloudWatch Pipelines AI 支援の実践的利用
マイクロサービス環境では、サービスごとにログフォーマットがバラバラ、というのがあるある。従来はサービスごとにパイプライン設定を個別に書いてメンテしていましたが、AI 支援機能を使えば新サービス追加時のセットアップ時間が短縮できそうです。
ログフォーマットが変わったときも、自然言語で新しい要件を書くだけで設定を再生成できます。「ログフォーマット変更 → パイプライン設定更新 → 動作確認」のサイクルが短くなれば、アプリ側のイテレーション速度にもプラスに効いてきます。
セキュリティとコンプライアンスの観点では、PII(個人識別情報)マスキングを自然言語で指定できるのが便利です。GDPR、CCPA、個人情報保護法などの規制対応で「email addresses, credit card numbers, and phone numbers should be masked」のような指示を書くと、マスキングパターンが生成されます。
コスト最適化の面では、ログの前処理(フィルタリング、集約)をパイプライン段階で行えば、ログストレージとクエリコストを減らせます。「keep only ERROR and CRITICAL logs, drop DEBUG and INFO」といった指示で、フィルタリング設定を作ってくれる。ただし AI 生成された設定は必ずサンプルログでテストしてから本番投入するのが鉄則です。特殊なエッジケース(タイムゾーン、エスケープシーケンス)は人目で確認しないと事故ります。
全アップデート一覧
以下の表に登場する、やや馴染みの薄いサービスの補足です。
Amazon Bedrock AgentCore とは? Bedrock 上で AI エージェントを構築するためのマネージドプラットフォーム。エージェントのランタイム、ツール統合、メモリ、観測可能性を一括で提供する。Strands Agents SDK や LangGraph といった OSS エージェントフレームワークのホスティング先として位置付けられている。
Amazon Corretto とは? AWS が提供する OpenJDK のプロダクション対応ディストリビューション。Java 8/11/17/21 等の LTS バージョンを AWS が無償でサポートし、四半期ごとにセキュリティパッチを配布している。Oracle JDK の代替として採用するケースが多い。
Confluent Cloud とは? Apache Kafka のマネージドサービスを提供する SaaS。イベントストリーミング基盤として、AWS Kinesis / MSK の代替またはマルチクラウドのハブとして使われる。今回の Secrets Manager 連携で、Kafka API キー等を AWS 側の権限管理に統合可能に。
| # | サービス | タイトル | 概要 |
|---|---|---|---|
| 1 | EC2 | Managed resource visibility settings | マネージドサービスがプロビジョニングしたEC2リソースの表示/非表示を制御可能に |
| 2 | EC2 | C8i instances in Ireland and New Zealand | Intel Xeon 6搭載の計算最適化インスタンスC8iが新リージョンで利用可能 |
| 3 | EC2 | C8i-flex instances in Europe and New Zealand | C8i-flexインスタンスが3つの新リージョンで利用開始 |
| 4 | Bedrock | AgentCore new features | マネージドハーネス、CLI、スキルなどエージェント構築を助ける新機能 |
| 5 | SageMaker | Serverless fine-tuning for Qwen3.5 | Qwen3.5モデルのサーバーレス微調整をサポート |
| 6 | OpenSearch | Rollback for service software updates | サービスソフトウェアアップデートのロールバック機能を追加 |
| 7 | Corretto | April 2026 Quarterly Updates | Corretto全バージョンの四半期セキュリティアップデート |
| 8 | EC2 | SQL Server HA health notifications | SQL Server HAのヘルス通知機能をAWS Health Dashboardで提供 |
| 9 | Network Firewall | Marketplace managed rules enhancements | パートナー提供のマネージドルールが最大1,000万ドメイン、100万IPに対応 |
| 10 | SageMaker | Generative AI inference recommendations | 生成AIモデルの推論最適化を自動提案する機能 |
| 11 | Secrets Manager | MongoDB Atlas and Confluent Cloud support | MongoDB AtlasとConfluent Cloudの管理対象外部シークレット機能 |
| 12 | SageMaker | Five new Qwen models in JumpStart | コーディングエージェントと推論に特化した5つのQwenモデル |
| 13 | EKS | Hybrid Nodes gateway | ハイブリッドKubernetes環境のネットワーキングを自動化するゲートウェイ |
| 14 | CloudWatch | AI-assisted pipeline configuration | 自然言語でログパイプラインのプロセッサ設定を自動生成 |
まとめ
方向性が読み取れるのは、「運用自動化」と「ハイブリッド環境の統合」の 2 軸です。
EC2 のマネージドリソース可視性制御は、共有責任モデルを可視化レベルまで落とし込んだ変更。EKS Hybrid Nodes Gateway は、オンプレ/クラウドまたぎのルート設定を Helm chart で自動化する構成。CloudWatch Pipelines の AI 支援機能は、これまで試行錯誤だったプロセッサ設定を自然言語で書けるようにする機能。どれも「今まで人手でやっていた作業を AWS 側が引き取る」方向の改善です。
生成 AI まわりでは Bedrock AgentCore の機能拡張、SageMaker JumpStart の Qwen モデル追加、推論最適化の自動提案など、エージェント構築と LLM 運用の実装を助ける機能が並びました。サーバーレス微調整と JumpStart のモデル拡充は、MLOps チームがプロトタイピングから本番まで持っていく速度に直結する部分です。
セキュリティ系では、Secrets Manager の MongoDB Atlas / Confluent Cloud 対応、Network Firewall の Marketplace ルール強化が入りました。マルチクラウド構成やハイブリッド構成でシークレット/ネットワーク管理を AWS 側に寄せられるアップデート。
SRE 視点では、今日の 3 つの深掘りはどれも運用プロセスの見直しトリガーになり得ます。まず自組織の Terraform / ランブックが「マネージドリソース可視性」の変更で影響を受けるかを見て、当てはまるなら影響範囲を確認するところから始めるのが現実的です。