2026年4月22日 AWS アップデート情報
はじめに
2026年4月22日の AWS アップデートは 10件。データベース・Lambda・SageMaker まわりに動きがあった日です。
特に目を引いたのは次の 2 つ。
- Lambda が S3 バケットをファイルシステムとしてマウントできる新機能(S3 Files)
- Aurora Serverless の最大30%のパフォーマンス向上(プラットフォームバージョン4)
S3 Files は、SDK 経由のダウンロード/アップロードで組んでいた処理パターンが根本から変わるタイプのアップデートです。AI/ML ワークロードで使い物になるかは検証次第ですが、Lambda の /tmp 10GB 上限や関数間ファイル共有の実装負荷が減るのは大きい。Aurora Serverless v4 は scale-to-zero(0 ACU)対応が入り、AI エージェントのようなバースト/アイドルが激しいワークロードが素直に Serverless に乗せられるようになりました。
他に、Athena Spark の PrivateLink 対応、SageMaker の IAM Identity Center マルチリージョンレプリケーション、Amazon Connect Outbound Campaigns の優先度付け、AWS Backup の新サービス対応などがあります。データレジデンシー/コンプライアンス寄りのアップデートが多い印象の回です。
注目アップデート深掘り
1. Lambda が S3 バケットをファイルシステムとしてマウント可能に(S3 Files)
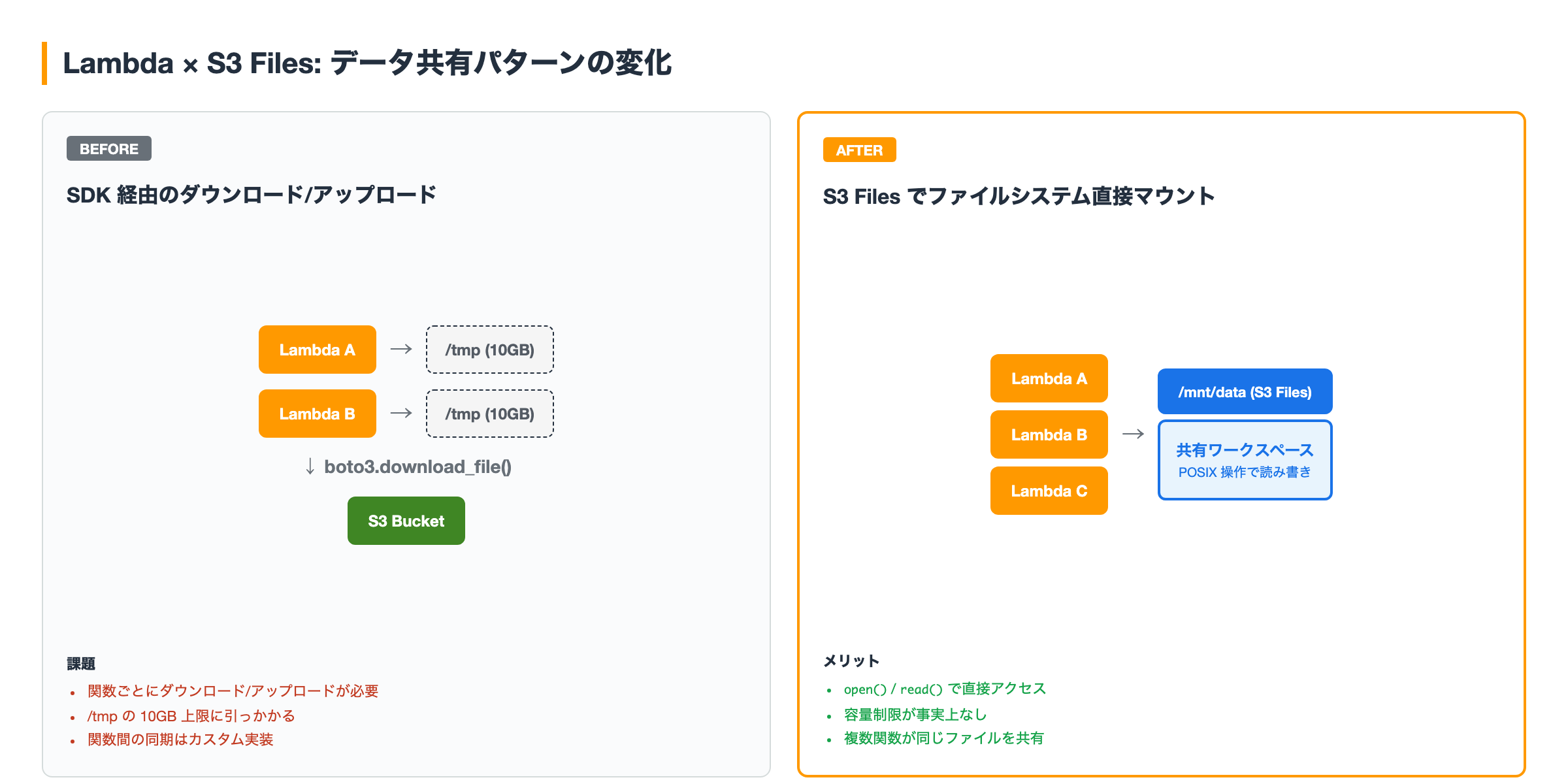
何が変わるのか
これまで Lambda から S3 上のファイルを扱う場合、AWS SDK で明示的にダウンロード/アップロードするのが定石でした。この方式には 2 つの痛みがあり、1つはファイルサイズが大きいと /tmp の 10GB 上限に引っかかること、もう1つは複数関数間でファイルを共有したい場合にカスタムな同期ロジックが必要なことでした。
S3 Files は、Lambda 関数が S3 バケットをファイルシステムとして直接マウントできる機能です。バックエンドは Amazon EFS ベースで、ファイルシステムとしての扱いやすさと S3 のスケーラビリティ・耐久性・コスト効率を合わせた作り。標準の POSIX ファイル操作(open(), read(), write())でそのままアクセスでき、複数の Lambda 関数が同じファイルシステムを共有できます。
刺さりそうなユースケース:
- AI エージェントの状態管理:会話履歴やメモリを S3 Files に保存し、複数の呼び出しをまたいで状態を維持
- パイプライン間のデータ共有:前処理・推論・後処理といった複数ステップで中間結果を共有ワークスペースに置く
- ダウンロード不要の直接処理:機械学習モデルや大容量データセットをストリーミング形式でアクセス
実装手順
S3 Files を Lambda 関数で利用するには、以下の手順を実施します。
1. S3 バケットの作成と S3 Files ファイルシステムの準備
まず、マウント対象となる S3 バケットを用意します。S3 Files は Amazon EFS をベースにしているため、Lambda コンソールまたは AWS CLI で S3 Files ファイルシステムを作成します。
$ aws s3 mb s3://my-lambda-shared-workspace
2. Lambda 関数の設定で S3 Files をマウント
Lambda コンソールまたは AWS SAM テンプレートで、関数に S3 Files ファイルシステムをマウントする設定を追加します。
AWS SAM テンプレート例:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
MyLambdaFunction:
Type: AWS::Serverless::Function
Properties:
Runtime: python3.12
Handler: app.handler
MemorySize: 1024
Timeout: 300
FileSystemConfigs:
- Arn: arn:aws:elasticfilesystem:us-east-1:123456789012:access-point/fsap-xxxxxxxxxxxx
LocalMountPath: /mnt/data
Policies:
- Statement:
- Effect: Allow
Action:
- elasticfilesystem:ClientMount
- elasticfilesystem:ClientWrite
Resource: arn:aws:elasticfilesystem:us-east-1:123456789012:file-system/fs-xxxxxxxxxxxx
3. Lambda 関数コードで標準ファイル操作を実行
Python の例:
import os
def handler(event, context):
# S3 Files マウントポイントへのアクセス
workspace = "/mnt/data"
# ファイル書き込み(他の Lambda からも参照可能)
with open(f"{workspace}/agent_memory.json", "w") as f:
f.write('{"session_id": "abc123", "state": "processing"}')
# ファイル読み込み
if os.path.exists(f"{workspace}/shared_model.bin"):
with open(f"{workspace}/shared_model.bin", "rb") as f:
model_data = f.read()
# モデルを直接メモリにロードして推論処理
return {"statusCode": 200, "body": "Processed"}
4. Lambda Durable Functions との組み合わせ
新たに GA となった Lambda Durable Execution SDK for Java と組み合わせることで、長時間実行ワークフローの途中状態を S3 Files に永続化し、複数ステップにまたがる AI パイプラインを構築できます。
import software.amazon.awssdk.services.lambda.durable.*;
public class WorkflowHandler implements RequestHandler<Input, Output> {
@Override
public Output handleRequest(Input input, Context context) {
DurableExecutionContext durable = DurableExecutionContext.builder().build();
// Step 1: データ前処理を実行し、S3 Files に結果保存
durable.invokeFunction("preprocess", input);
// Step 2: 外部 API 呼び出しを待機(最大1年間)
durable.waitForCallback("external-api-callback");
// Step 3: S3 Files から前処理結果を読み込んで最終処理
durable.invokeFunction("finalize", input);
return new Output("Workflow completed");
}
}
従来方式との比較
| 項目 | 従来方式(SDK 経由) | S3 Files |
|---|---|---|
| ファイルアクセス方法 | boto3.client('s3').download_file() 等 | 標準 POSIX 操作(open(), read()) |
| 複数関数間の共有 | カスタム同期ロジックが必要 | 自動的に共有、ロック不要 |
| /tmp 容量制限 | 10GB(ダウンロードサイズに制約) | マウントポイント経由でほぼ無制限 |
| コスト | S3 API リクエスト料金 + データ転送料金 | S3 料金のみ(追加料金なし) |
| レイテンシ | ダウンロード時間が必要 | ストリーミングアクセス可能 |
活用シナリオ
- AI エージェントのメモリ管理:LangChain や LlamaIndex で構築したエージェントが、会話履歴やベクトル埋め込みを S3 Files に保存し、セッションをまたいで状態を維持
- データパイプライン:Lambda で大規模ログファイルを前処理 → 中間結果を S3 Files に保存 → 別の Lambda が後処理
- 機械学習推論:学習済みモデル(数GB)を S3 Files に配置し、複数の Lambda 関数が同時にロードして推論処理を実行
2. Aurora Serverless が最大30%のパフォーマンス向上とスマートスケーリングを実現
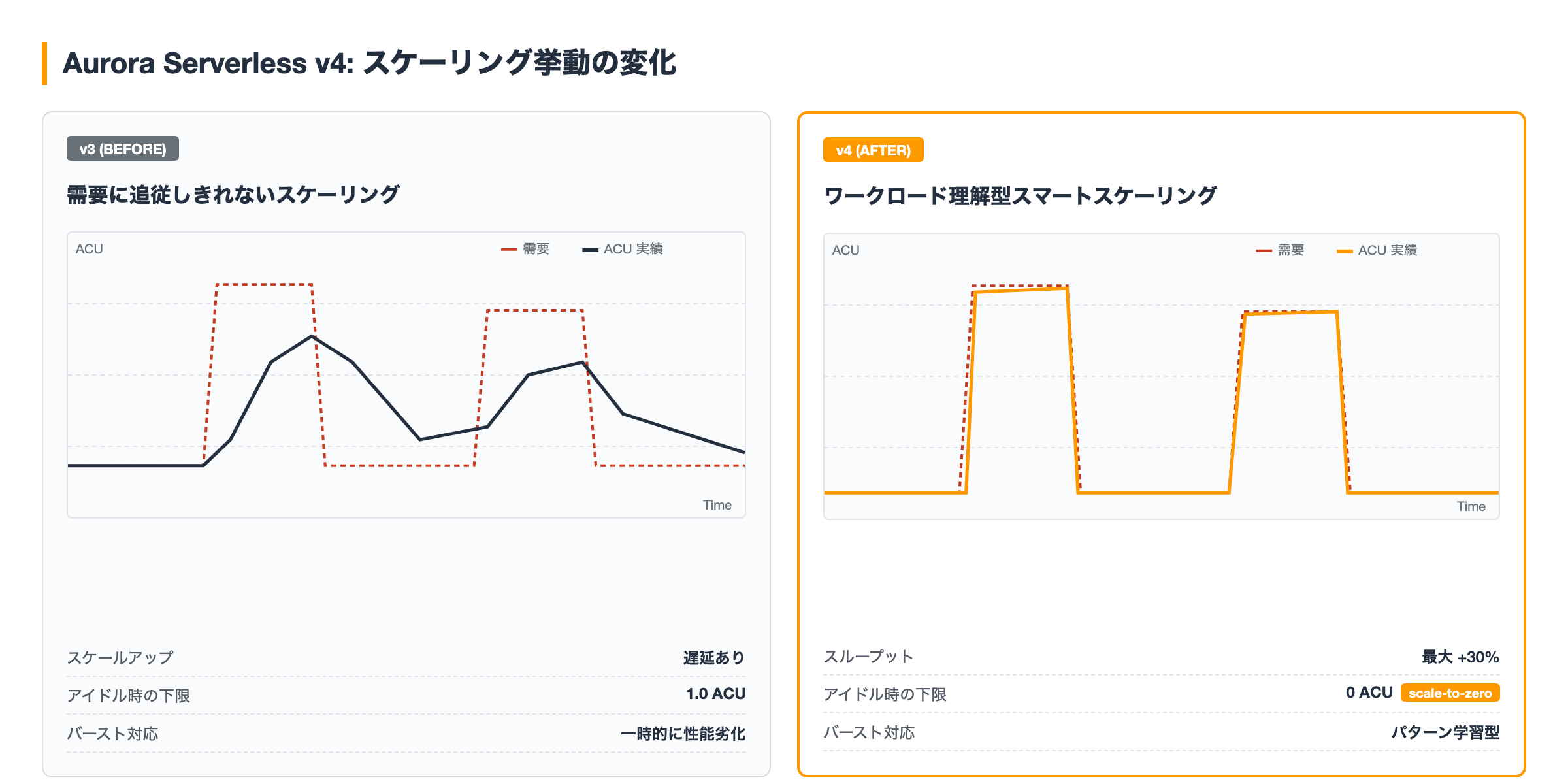
v4 で入った改善点
Amazon Aurora Serverless は、使用量に応じて DB 容量を自動でスケールし、アイドル時にはゼロまで落としてコストを抑えるサービスです。プラットフォームバージョン4で入った変更は主に次の 2 点。
- スループット最大 +30%(同じワークロードでの比較)
- ワークロード理解型のスマートスケーリング(不規則なバースト/アイドルを学習して追従)
AI エージェント的なワークロードは、リクエスト時だけ集中的に DB を叩いて、あとは長時間アイドル、という不規則なパターンを持ちます。従来のスケーリングアルゴリズムではスケールアップ判断が遅れて一時的に性能が劣化することがありましたが、v4 ではこの追従性が改善されています。
Web アプリや API サービスのように複数タスクが同時にリソースを競合する環境でも、容量配分の挙動が変わりました。これまでこうしたワークロードで Aurora Provisioned を選んでいたケースの一部は、v4 で Serverless のまま運用できるようになります。
パフォーマンス検証手順
プラットフォームバージョン3と4のパフォーマンス差を実測するには、以下の手順でベンチマークを実施します。
1. 既存クラスターのバージョン確認
$ aws rds describe-db-clusters \
--db-cluster-identifier my-aurora-serverless \
--query 'DBClusters[0].EngineVersion'
2. v4 へのアップグレード(Blue/Green デプロイメント推奨)
$ aws rds create-blue-green-deployment \
--blue-green-deployment-name aurora-v4-upgrade \
--source-arn arn:aws:rds:us-east-1:123456789012:cluster:my-aurora-serverless \
--target-engine-version 8.0.mysql_aurora.4.0.0
Blue/Green デプロイメントを使用することで、本番環境への影響を最小限に抑えながら、新バージョンでのパフォーマンステストが可能です。
3. 負荷テストの実施
Apache Bench や Locust を使用して、同一のワークロードを v3 と v4 に対して実行し、スループットとレイテンシを比較します。
# v3 クラスターに対する負荷テスト
$ ab -n 10000 -c 100 https://api.example.com/v3/endpoint
# v4 クラスターに対する負荷テスト
$ ab -n 10000 -c 100 https://api.example.com/v4/endpoint
4. CloudWatch メトリクスでの確認
Aurora のパフォーマンスメトリクスを CloudWatch で可視化し、以下の指標を比較します:
DatabaseConnections:同時接続数CommitThroughput:トランザクションスループットSelectLatency:SELECT クエリのレイテンシACUUtilization:Aurora Capacity Units の使用率
import boto3
from datetime import datetime, timedelta
cloudwatch = boto3.client('cloudwatch')
# v3 と v4 のレイテンシを取得して比較
response = cloudwatch.get_metric_statistics(
Namespace='AWS/RDS',
MetricName='SelectLatency',
Dimensions=[{'Name': 'DBClusterIdentifier', 'Value': 'my-aurora-v4'}],
StartTime=datetime.utcnow() - timedelta(hours=1),
EndTime=datetime.utcnow(),
Period=60,
Statistics=['Average']
)
for datapoint in response['Datapoints']:
print(f"Time: {datapoint['Timestamp']}, Latency: {datapoint['Average']} ms")
スマートスケーリングの動作確認
新しいスケーリングアルゴリズムの挙動を確認するには、以下のようなバースト型ワークロードを実行します。
AI エージェントシミュレーション
import time
import mysql.connector
# Aurora Serverless v4 に接続
conn = mysql.connector.connect(
host='my-cluster.cluster-xxxx.us-east-1.rds.amazonaws.com',
user='admin',
password='password',
database='agents'
)
cursor = conn.cursor()
# バースト処理:短時間に大量のクエリを実行
for i in range(1000):
cursor.execute("INSERT INTO conversations (session_id, message) VALUES (%s, %s)",
(f"session-{i}", f"User message {i}"))
cursor.execute("SELECT * FROM conversations WHERE session_id = %s", (f"session-{i}",))
result = cursor.fetchall()
conn.commit()
# 長時間アイドル(スケールダウンを観察)
print("Waiting for scale-down...")
time.sleep(600) # 10分間待機
# 再度バースト処理(スケールアップの速度を確認)
for i in range(1000, 2000):
cursor.execute("INSERT INTO conversations (session_id, message) VALUES (%s, %s)",
(f"session-{i}", f"User message {i}"))
conn.close()
CloudWatch で ServerlessDatabaseCapacity メトリクスを確認し、スケールアップ・ダウンのタイミングと速度を可視化します。
コスト試算
Aurora Serverless v4 のコストメリットを試算するには、以下の要素を考慮します:
- ACU(Aurora Capacity Units)の最小・最大設定:アイドル時の最小 ACU を 0.5 に設定することで、ほぼ使用していない時間帯のコストをほぼゼロにできる
- 実際の稼働パターン:1日のうち業務時間(8時間)のみ高負荷、それ以外はアイドルの場合、従来の Provisioned インスタンス(24時間稼働)と比較して約70%のコスト削減が可能
# コスト試算例(us-east-1 リージョン)
acu_price_per_hour = 0.12 # USD per ACU-hour
# シナリオ1: Provisioned (r6g.xlarge 相当 = 常時8 ACU)
provisioned_cost = 8 * acu_price_per_hour * 24 * 30 # 月額
print(f"Provisioned monthly cost: ${provisioned_cost:.2f}")
# シナリオ2: Serverless v4 (業務時間8h は8 ACU、その他16h は0.5 ACU)
serverless_cost = (8 * acu_price_per_hour * 8 + 0.5 * acu_price_per_hour * 16) * 30
print(f"Serverless v4 monthly cost: ${serverless_cost:.2f}")
print(f"Cost reduction: {(1 - serverless_cost / provisioned_cost) * 100:.1f}%")
SRE視点での活用ポイント
S3 Files の運用シナリオ
障害対応ランブックの自動化に使えそうです。複数の Lambda 関数が協調して障害復旧処理を回す際、S3 Files を共有ワークスペースにしておけば、第一段階の Lambda が診断ログを書き込み、第二段階が読み込んで復旧スクリプトを実行、というフローをカスタムな同期処理なしで組めます。Lambda Durable Functions と組み合わせると、長時間の復旧処理のチェックポイントを S3 Files に置いて、途中で失敗しても再開できる構成になります。
コスト面では、SDK 経由のダウンロード/アップロードで発生していた S3 API リクエスト数とデータ転送料金が、ファイルシステム形式のアクセスで発生しなくなります。大量の小ファイルを処理するワークロードでは API リクエスト数が減って運用コストに効いてくる見込みです。
導入時の注意点は 2 つ。S3 Files は EFS ベースなので Lambda を VPC 内に配置する必要があります。VPC Lambda はコールドスタート時間が増えるため、低レイテンシが必要なリアルタイム処理では事前に性能検証が必要です。もう1つは、複数関数が同じファイルに同時書き込みする場合、適切なロック機構を自前で用意する必要がある点。ファイルシステムだからといって競合制御が魔法のように解決されるわけではありません。
Aurora Serverless v4 のスケーリング戦略
v4 のスマートスケーリングは、オンコール対応の負荷削減と運用自動化に効いてきます。
従来の Provisioned インスタンスではリソース逼迫時に手動スケールアップが必要でしたが、Serverless v4 では自動追従するので、深夜のリソース枯渇アラートやエスカレーションの頻度が下がります。CloudWatch アラームを ACUUtilization メトリクスに設定して、閾値を超えたときだけ通知する構成にすれば、本当に対応が必要な異常だけに集中できます。
適用判断の目安は以下のようなワークロード特性:
- 業務時間帯とそれ以外で負荷が明確に異なる(社内向け管理画面など)
- バースト的なトラフィックが発生する(キャンペーン時のアクセス集中など)
- 開発・ステージング環境で常時稼働させる必要がない
一方、常に高負荷が続く 24 時間稼働の顧客向け API などは、Provisioned のほうがコストパフォーマンスが良い場合もあります。CloudWatch のコスト最適化ダッシュボードで実際の ACU 使用量を可視化して、半年〜1年単位で見直すのが現実的です。
Terraform で書く場合、v4 のスケーリング設定は以下のように記述できます。
resource "aws_rds_cluster" "aurora_serverless_v4" {
cluster_identifier = "my-aurora-serverless-v4"
engine = "aurora-mysql"
engine_version = "8.0.mysql_aurora.4.0.0"
database_name = "mydb"
master_username = "admin"
master_password = var.db_password
serverlessv2_scaling_configuration {
min_capacity = 0.5
max_capacity = 16
}
tags = {
Environment = "production"
ManagedBy = "terraform"
}
}
全アップデート一覧
以下の表に登場する、やや馴染みの薄いサービスの補足です。
Aurora DSQL とは? AWS の分散型 SQL データベース。PostgreSQL 互換で、リージョンをまたいだマルチアクティブ構成を前提に設計されたサーバーレス DB。従来の Aurora とは別系統の製品で、グローバル分散のワークロード向け。
Athena Spark とは? Amazon Athena のノートブックエンドポイント。通常の Athena が SQL ベースなのに対し、Spark エンジンを使って PySpark や Scala でインタラクティブにデータ分析できる機能。ETL やデータサイエンス用途向け。
AWS Transform custom とは? AWS Transform(旧 Migration Hub)のカスタムトランスフォーメーション機能。レガシーコードのモダナイゼーションを、自前で用意したプロンプト・ルールに基づいて AI で実行できる。.NET → Java、メインフレーム → クラウド等の大規模コード変換用途。
Lambda Durable Execution とは? 長時間(最大1年)実行できるワークフローを Lambda 上で書くための仕組み。進捗が自動でチェックポイントされ、途中で Lambda がタイムアウトしても次の実行で続きから再開できる。Step Functions に近い領域だが、コードファーストで書ける点が異なる。
| # | タイトル | 概要 | リンク |
|---|---|---|---|
| 1 | SageMaker が IAM Identity Center のマルチリージョンレプリケーションをサポート | SageMaker Unified Studio ドメインを IdC インスタンスとは異なるリージョンにデプロイ可能に。データレジデンシー要件を満たしながら一元化された SSO アクセスを維持。 | 詳細 |
| 2 | AWS Transform custom が6つの追加リージョンで利用可能 | 東京、ムンバイ、ソウル、シドニー、カナダ中部、ロンドンで提供開始。大規模なコード現代化をカスタムトランスフォーメーションで実現。 | 詳細 |
| 3 | Athena Spark が AWS PrivateLink に対応 | VPC 内のクライアントからパブリックインターネットを経由せずに Athena Spark の全エンドポイントにアクセス可能に。Spark Connect、Live UI、History Server すべてに対応。 | 詳細 |
| 4 | AWS Backup が Redshift Serverless と Aurora DSQL をサポート | AWS Organizations のバックアップポリシーで、Redshift Serverless と Aurora DSQL をリソースタイプとして直接指定可能に。組織全体のバックアップガバナンスを強化。 | 詳細 |
| 5 | AWS Marketplace が EU・ノルウェー・英国での VAT 支払いを自動化 | デジタルサービス販売における VAT 処理を自動化。請求書を提出すると自動検証・振込を実施。複数取引の統合請求と監査対応レポート機能を提供。 | 詳細 |
| 6 | EC2 G7e インスタンスがロサンゼルスの Local Zones で利用可能 | NVIDIA RTX PRO 6000 Blackwell Server Edition GPU と第5世代 Intel Xeon を搭載。VFX 編集・LLM 推論・エッジ AI など、低レイテンシが求められるワークロードに対応。 | 詳細 |
| 7 | Lambda Durable Execution SDK for Java が GA | 長時間実行ワークフローを構築可能に。進捗の自動チェックポイント、最大1年間の実行一時停止機能を提供。Java 17+ 対応、ローカルテストエミュレーター搭載。 | 詳細 |
| 8 | Lambda が S3 バケットをファイルシステムとしてマウント可能に | S3 Files により、Lambda 関数が S3 をファイルシステムとして直接マウント。複数の Lambda 関数が共有ワークスペースを通じてデータを共有可能。AI/ML ワークロードに最適。 | 詳細 |
| 9 | Aurora Serverless が最大30%のパフォーマンス向上とスマートスケーリングを実現 | プラットフォームバージョン4で提供。ワークロード理解型スケーリング、AI エージェント最適化、ゼロスケール対応。追加料金なし。 | 詳細 |
| 10 | Amazon Connect Outbound Campaigns が連絡先優先順位付けをサポート | 最大10個のプロフィール属性に基づいて架電順序を設定可能。顧客 LTV、アカウント階級、予約日時などでセグメントをソート。追加コストなし。 | 詳細 |
まとめ
方向性が読み取れるのは、サーバーレスの適用範囲拡大と、エンタープライズ向けのガバナンス系補強の 2 軸です。
Lambda × S3 Files、Lambda Durable Execution SDK for Java の GA、Aurora Serverless v4 の性能向上はすべて、サーバーレスで組めるワークロードの幅を広げる方向の変更です。Lambda の 15 分制限や /tmp の 10GB 上限といった、これまで ECS/EKS へ流していた理由の一部が Durable + S3 Files で対処可能になります。AI/ML パイプラインや長時間ワークフローを Lambda ベースで組み直す選択肢が現実的になってきました。
もう一方の軸として、SageMaker の IdC マルチリージョンレプリケーション、Athena Spark の PrivateLink 対応、AWS Backup の Redshift Serverless / Aurora DSQL 対応など、データレジデンシーとコンプライアンス寄りの補強が並びました。金融・ヘルスケアなどデータ越境に厳しい業界で AWS を採用しやすくなる系の変更です。
SRE 視点では、Aurora Serverless v4 のスマートスケーリングが最も運用に効いてきそうです。Terraform / CloudFormation で最小/最大 ACU を適切に設定しておけば、夜間の手動スケールや緊急オンコールの頻度が実測で下がるかどうか、導入後に CloudWatch のコスト最適化ダッシュボードで追っていくのが現実的な進め方です。